
Weg's Tutorials
Life After Experience Replay
Letting Go of The Hand
Prerequisites
This tutorial follows the first
Experience Replay Tutorial.
If you haven't read that one you might want to go give it a read.
Get a snack, relax. Make yourself comfy. This one is mostly a mental exercise.
Also you have two weeks left to live.
Getting Started
In the last tutorial we made a replay buffer to fix some of our agent's stability issues.
Our strategy turned the reinforcement learning problem into more classic machine learning,
complete with an actual dataset and opportunity for some data management. The beneficial effects of shuffled
batches are basically the same for reinforcement learning as they are for computer vision
and NLP. However, the metaphor is a bit different and so how it helps might not be so obvious.
Data Quality
In Classic Machine Learning
Other than batching (which has a whole slew of advantages on its own, and you should go look that up), the
two most import things we did were shuffle and balance the data.
By adding a replay buffer we drastically changed the order that the agent was exposed to the transitions.
No changes were made to the agent architecture.
Changing data order and balance alone has huge impacts on the agent's score.
Data Order
Imagine you are making a typical machine
learning dog vs. cat image classifier. You have
10,000 images of dogs and 10,000 images of cats. Instead of shuffling
the data, you present the data of each class one after another.
So first you train the network on all 10,000 images of
dogs, and then when that is done you train it on all
10,000 images of cats.
You probably already know this isn't going to work very well. The network
will learn to guess dog 100% of the time after the first 100 images or
so, and then it will have 100% accuracy for the next 9,900 images of dogs.
Since it guesses correctly it will have near zero error, and that means
near zero learning.
Then when it finally gets to the cat images, it will have 100% error as it
figures out it is supposed to not guess dog every time. Hopefully all the
neurons that would have been used for cats don't have weights at 0.000001 by this point
(which basically means they are dead and can't be revived). But if it does manage
to revive those neurons, then they will take over and the network will just learn
to guess cat 100% of the time. Lets assume it does this by image 200 of the cat
section. Then for the rest of the 9800 cat images, it will always guess cat, have an
error near zero, and never learn anything else about either cat's or dogs. At this point
the network is unusable. It didn't matter if the data was clean or how much of
it there was. All that training time, and almost all the data went unused.
The lesson to learn from this is the network learns not from data,
but when the data switches from one concept to another concept. The whole task is to
learn by comparing things. You can't learn
from comparing something to itself. The solution is to shuffle the data. Cat, dog,
cat, dog. Every new data should be a change in concept.
Data Balance
Consider the case of classifying images of cats vs. dogs again. If you have 10,000 pictures of dogs,
and only 100 pictures of cats, you have a huge data imbalance issue.
Even if you were to shuffle the pictures, such that the 100 cat images are spaced evenly throughout
the data, the network has no reason to learn to identify cats at all, or even to learn dogs for that matter.
All it has to do is guess dog 100% of the time, and it will end up with about 99% success rate.
You might be tricked, see the 99%, and think the network is great at differentiation between
cats and dogs. It's not. It's terrible at it.
Maybe you think i'm just exaggerating:
"What are the odds that i have 10,000 images of dogs, and only 100 images of
cats? Maybe it would be more reasonable that I have 1000 images of
dogs and 500 images of cats."
Well, even in that scenario, if the network guessed dog 100% of the time it would get a 67% accuracy.
Does that mean it understands 67% of the difference between cat and dog? No.
Does it mean it understands even 17% (67% - 50%) (50% is a coin flip) of the difference between
cat and dog? No.
It applied zero knowledge about cats and dogs. It just chose dog every time. The only correct conclusion
you can come to is that it knows you have more pictures of one class than the other.
You could swap the 1000 images of dogs out for pictures of asparagus and it would still get the high accuracy.
These aren't just abstract aspects of working in data science by the way. You probably shuffle and balance
data naturally when you try to teach yourself things. Think back to practicing multiplication tables or
memorizing new
vocabulary in foreign language
class in school. When you use flashcards, do you drill yourself on one card 10,000 times, expect to have
learned it,
and then move on to the next card in the stack? No. Obviously it wouldn't work. So you shuffle the cards,
and make sure you practice a diverse set of concepts. Boredom seems to be a way of mechanically forcing you to
do this. :^)
Data Quality
In Deep Reinforcement Learning
Given how drastic the effects of bad data quality are on classic machine learning, you might be surprised to
hear the situation is much worse in reinforcement learning.
Data Order
You might be wondering... How can someone consider the order of data in cartpole? All the data comes
from the same source. It's provided by the environment, and so each sample is ordered in time.
Doesn't scrambling them break the agents notion of time? Plus, every transition is just 4 numbers about a
pole.
It isn't as diverse as images, so aren't the samples basically almost the same anyways?
RL is not like in classification where it is so obvious what distinguishes one sample from another, cat vs.
dog. You don't even know what the classes are beforehand. However, it is still a lot like a
classification problem.
From the perspective of an agent that already knows how to solve cartpole, each transition represents
a distinct concept, a distinct "classification". For the expert agent, it is a fuzzy classification
problem.
Consider you had printed out 1000 screenshots of the cartpole game, and cut them out into flashcards.
If i asked you to divide the stack of cards into categories, you probably could. And I bet you would
be pretty good at it too. First, you would divide the cards up into obvious categories such as "falling-left"
and "falling-right", and then you would find additional categories like "doomed to loose", and
"balanced great". (Notice that some categories are mutually exclusive. You might have to cut pieces out of
old categories, or dissolve them entirely, to make new ones when you see a new pattern.)
Now consider that you try this task again with the same cards,
but the first 200 cards you pull out of the stack all look like this:
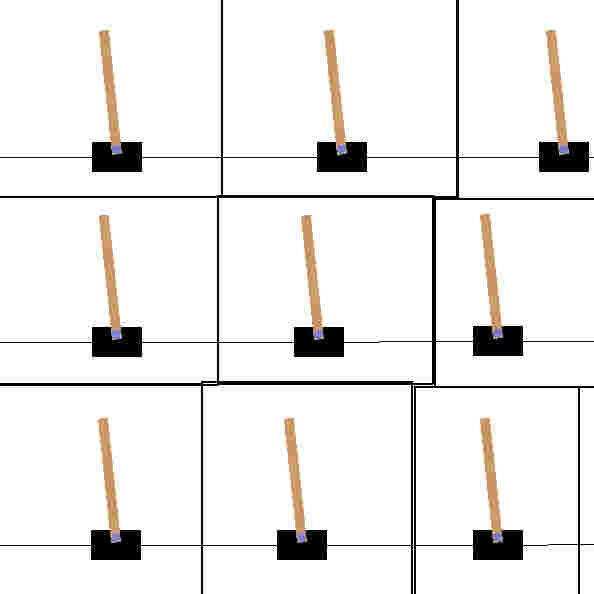
What categories are there to make?? They all look the same.
:^) hehe that's because I used the same picture over and over.
This is not unrealistic for an rl agent. Before we added the
replay buffer, it is incredibly likely that the agent would receive 9 to 20 frames in a row of the pole
falling on the same side. The episode terminates when the pole is barely tipping over.
Then when the next episode starts, there is a 50% chance it gets another 9-20 nearly identical
frames...
This happens over and over and over. It's a serious data order problem.
Data Balance
Now, let's assume you didnt know about replay buffers, but you wanted to fix
data order problems. You come up with what you think is a solution.
You decide to collect 10 transitions at a time into a minibuffer.
That means, as the game is played, each step returns a transition and you put that transition
into a list. Once the list hits size 10, the list of samples is shuffled and then given to the agent.
Then they are discarded. The list is cleared.
This shuffles the data right? So shouldn't it fix data order problems?
No, because you still have the same content issues.
The set of transitions collected represent the same, or very similar, concepts.
The order has changed, but the class imbalance is still there.
Maybe you could fix that by making the mini buffer bigger. That way it could
catch some samples from different episodes, and thus have a chance of being
transitions from more diverse circumstances.
But to do that, how long should this mini buffer need to be? Is 50 frames enough? 1000?
What if you try a different environment
where the physics run at half the speed? Do you make the mini buffer twice as large?
Are you really going to micromanage the size of this mini buffer? Do you really
want to investigate the environment deeply to figure out how big it needs to be?
What if your agent is taking in real life data from a 144fps camera?
Thousands and thousands of the frames in your big minibuffer are going to be nearly identical when the agent
isn't moving that
much. So your agent will be spending all that time reviewing thousands of nearly identical frames.
Isn't it a huge waste of time?
And if you are really unlucky all those similar frames could push the network
weights into a stale spot where they will never recover from.
All the great feature detectors it grew in other scenarios could be lost in time.
The experience replay buffer manages to address both data
order and balance simultaniously. The agent is much more likely to review a diverse set of transitions
at each learn step, and as such reviews diverse "classes" of scenarios.
And the agent can continue to review old transitions even
when it is stuck in an environment scenario that is pretty stale on its own.
Feedback Loop
But why did I say these order and balance effects are even worse in reinforcement learning than in
other machine learning? So far it seems like the same effects right?
The reason these effects are much worse in rl is the agent designs its own dataset.
If you are training a network to identify cats vs. dogs that network doesn't get a chance to screw up the data.
Assuming you balanced and shuffled the data, by the end of training you are guaranteed the network has seen every
class equally.
There is no such guarantee for an RL agent.
Consider our replay buffer as it is. Our agent picks 64 random transitions from the entire pool of transitions it
has experienced. Shouldn't that mean they are gonna have random classes? No.
While it might seem likely that the data is going to end up diverse given enough episodes, I would actually argue
the opposite is much more likely. Those 64 random samples are not being drawn from a balanced pool. Sure, about
50%
of the samples will be a pole-falling-left, and 50% of a pole-falling-right.
But once the agent gets good... 90% of the transitions in the memory are going to be of a pole pointing almost
exactly straight up.
Which means 90% of the 64 random memories samples from the replay buffer... are going to be almost entirely just
poles pointing straight up.
That means the agent won't be practicing scenarios where the cart is near the edge of the play area. And
it wont be practicing scenarios where the pole is at a more extreme angle or velocity.
The result? It likely will not be effective in those scenarios anymore. This is the case even if it
used to be okay at those scenarios.
CATASTROPHIC FORGETTING strikes again, but in a much more sinister form.
When you go try the lunar lander
environment you can witness this firsthand. The lander agent will seem to forget the old basic balancing
skills it had spend so much time practicing, as it refines the much more specific strategy of inching towards
the ground. If you see the lander end up in a scenario that defies
its new very specific strategy, it might just flip out and behave completely stupidly. I suspect that
wouldn't happen if it was getting a constant flow of samples from good old times to remind it.
Objection
"Hey what's wrong with that? The agent doesn't need to practice balancing at extreme angles anymore. So
it's not only okay that it is focusing on refining its balancing technique within a more specific scenario,
but it is ideal."
Yes this is true. And not only is it a beneficial effect of a replay buffer, but it's something
RL agents seem to do naturally anyways. The agent specializes and focuses on
what it should. How beneficial that strategy rigidity is heavily depends on the environment, though...
You lose what you don't practice, to make room for what you do. It is possible there is a
fantastic feature detector that will work for both "very balanced poles" and "barely balanced poles",
but it will never be discovered unless both circumstances are considered frequently togethor.
The nature of the agent is that its goal is to undiversify the data. It want's to see the same circumstance
over and over. To minimize error is to minimize how much the circumstance changes.
As our agent is, it hates new scenarios. It is doing this on purpose.
Reinforcement learning makes your data "self-siloing", "self-unbalancing", and "self-ordering".
By getting good at the game, our current agent is also setting itself up to be more specialized.
To combat this you have to really force it to eat its vegetables.
Damned If You Do / Damned If You Don't
The bad news doesn't end there. :^(
Let's run under the assumption that we want the agent to specialize on refining its pole balance.
Maybe you don't care if the agent is good at recovering from disastrous scenarios because it
shouldn't be in any of those scenarios in the first place.
So in order to specialize, the agent needs to train on transitions that are similar to the kind of transitions
it will be likely to see.
Reviewing old disaster transitions from terrible early episodes might be necessary to prevent CATASTROPHIC
FORGETTING
but beyond a threshold amount it will actually make the agent worse. (worth investigating the threshold)
Assuming 90% of the transitions end up as "nearly-balanced-poles", the remaining 10% are old "fire-drill samples".
And they are going to be pretty hard to get rid of. To convert that 10% to 5% will require twice as many steps as
up to this point.
So that is twice as much training time. Meaning, it's going to require exponentially more new samples to burry
those old samples.
Those fire drills aren't really going anywere unless you manually purge them.
And more importantly, you don't know which of those old samples is good or bad anyways.
Some of them are worth keeping around. (worth investigating)
It's almost as if we need a second agent managing the replay buffer, choosing what memories to give
to the primary agent at what time, and what memories, if any, to dispose of. ;^) I suspect the memory will end up
as
part of the machine learning soon enough. If somebody hasn't done it already, I give it a few years. (or you could
try doing it yourself)
The Tutorial Is Within
Life is complicated. You fix some things, but break another.
There are many addons waiting to be discovered that will improve the agent, some more
complicated (and more work :^) than others. I want you to consider some of the problems
that our experience replay brought to light. What are the causes of those problems?
What addons can you create that will mitigate them, without breaking everything in the process.
Focus on solutions that are easy. If something requires too much work, it is probably the wrong solution.
I hope you aren't mad at me, but this time the tutorial provides you no code.
Maybe it is the most important tutorial yet.
That's how it is at the edge of science. No parents. No rules.
I want you to get a notebook and a pencil, and go sit outside, or go for a walk.
List circumstances that fool the agent.
List potential causes.
This time the tutorial is within your heart. awwwwwwwwww
I will go for a walk now, and do the same as you. Up ahead I'll tell you what i thought about.
But really, you better go do it. I'm not kidding. I'm actually going for a walk now with my notebook. Bye.
Hey
DONT SKIP AHEAD
GO HAVE SOME IDEAS
WHERE DO YOU THINK
THIS STUFF COMES FROM?
Some Of My Ideas
- What if most of the memories are the same? Should similar memories
be merged into one? How do you preserve the magnitude of that merged result?
How to detect similar memories? An autoencoder perhaps? Categorize them into
some groups, and then replace a group with a quintessential memory that represents that group?
This could potentially replace massive amounts of memories with just a handful important ones.
- The agent finds some hard part in a game level. It has to restart over
and over to get to that point again, just to practice the hard part.
Isn't that a waste of time, and a distraction for the agent?
Should the memory contain save points from the environment?
Obviously you cant save every point right? (too much memory)
Do you save points that are surprising to the agent?
Or maybe you keep a running window of saves, and then if you find out
one presents a "fork in the road", then it goes into a list of "branching memories"?
Most environments don't support loading from save points...
Do you have to have a network that models the environment to get
load functionality?
- The agent doesn't really have an idea of arbitrary goals.
Could the agent be modified to try and fit a reward function, enabling you
to swap out reward functions on the fly? After all, human goals change all
the time. Are the changes in human goals just subgoals to a singular reward
signal like the agent has? Or does the actual reward source change?
If the reward source changes, the agent's qvalues will all be wrong instantaniously,
so somehow the transitions should be passed through a reward function filter
that supports arbitrarily switching goals at any moment. After all,
learning how to optimize for one reward in an environment should provide
insight into maximizing multiple different rewards. By being good at chess,
I can try to win, or lose on purpose, or stall the game. You don't instantly
become bad if the goal changes. Goals share useful features, and strategies.
In fact, if the agent can handle multiple goals, it may get even higher performance
on any singular goal.
-
Since we now have a real dataset to work with, can that data be passed through normal
data augmentation pipelines? Flipping, and rotating and scaling the data to get
better quality features detectors? Would this help an agent that is learning to balance itself?
As direction of motion should be arbitrary. It would especially help for an environment with a camera
that can move, or a coordinate system that is not fixed. (Such as real life.)
- If an agent gets a bad reward, currently it will attribute that reward to the last decision made.
If it was really smart, a large negative reward would trigger some function that walks backwards through
the transitions looking for the true cause.
- A binary tree environment with the reward hidden in one of the leaves would be really difficult to solve for
the agent. "Branch points", "save loading", "transition trajectories", "route review", would all be effective
ways to help. But it would be an exploration issue as well. Somehow the env needs to be designed to incentivise
traversing the tree evenly, kind of like how ants roam outward from an ant pile to maximize surface area
explored.
I cant think of a way to implement this at the moment. Im getting kind of bored. Time to walk home.
Some of those are much easier to implement than others.
I want you to investigate some simpler ones as an exercise. This way you can get out
of the habit of looking up answers, and following tutorials. I love that you read my tutorials, but
remember the point of successive tutorials is that you should eventually graduate with a deeper
understanding that no longer needs tutorials.
Here are some ideas that aren't necessarily purely mine,
(are any ideas?) but they are simple enough that for you to try on your own without looking up how:
I bet you could solve any of these within just a few hours:
- Early on there isnt much experience to work with. Should the agent
collect states without acting to build up some memory? I bet you could do this one in less than 30 minutes,
and test to see if it actually works.
- Does the agent really need to eat asparagus so often after it has obviously tried it?
Try tapering off the chance of random action over time. Try tapering linearly. Try tapering exponentially.
- If the reward stagnates, should the chance of random action go up? Try checking the change in reward
each step, and then if it decreases for too long make the chance of random action increase.
- Bonus Harder One: An important but rare event occurs once. How to get the agent to focus on it when
it is buried in 10,000 other less important memories? Try sorting the memory and make
more surprising memories get learned from more often.
Once you implement one of your ideas, make sure to compare it to the previous version of the agent.
Make sure to run both 10 or more times so you can be sure your modification didn't just get lucky runs.
Try adding a multiplier to your modification so that you have a hyperparameter to tune.
Try it in different environments.
Document the entire process, and write a blog about it. BOOM now you are an official researcher.
I think you are coming to a deeper understanding of how these things work now, so the future tutorials can be
more pragmatic, and less foundational.
END
...BEGIN?
Tutorial Hub