
Weg's Tutorials
Experience Replay Tutorial
Your First Add-On
❗❗❗Message For Impatient Noobs❗❗❗
This tutorial has a lot of explanation before it gets down to the code.
The reason is this the beginning of real reinforcement learning. Going forward from here, the
changes to the agents get much more complex. If you dont understand "why" somebody invented some
modification to an agent, then most likely you will just be copying
other peoples code, and spending enourmous amounts of time debugging random errors at very little value to
yourself,
and your own understanding.
I have heard from more than a handful of beginners
that got stuck doing that for months at a time, struggling endlessly with more and more complicated agents in
hopes
of solving just one or two environments. I don't want that to be you.
For that reason, this tutorial takes a very scenic route. But I promise when you get there you will have some
new perspectives, questions, and context for why the researchers are investigating the solutions that they are.
You will probably also have some ideas for how to improve your own agents performance.
Prerequisites
This tutorial builds onto the naive Deep Q Learning agent from the
DQN Tutorial. It would be very helpful for
understanding
this one if you read that one. You wont need any additional tools or software that you did not need in
that tutorial.
Getting Started
Deep Q Learning works okay on its own, but it has some fundamental problems that make it not that practical by
itself.
Interestingly, almost all the base drl algorithms have the same fundamental issues:
- The agent can take way too many episodes to learn a task
- The agent can "forget" it's good solution and regress even after mastering a task
- The agent can be too unreliable, having equally many terrible runs as great runs
- The agent might have no real model of how it's environment works
- The agent probably only has a naive notion of exploration, consisting generally of making random moves some of
the time...
- The agent might feel cold and lonely inside, laying in bed all night unable to sleep, wondering if it is
somehow fundamentally incapable of love.
There are a bunch of different factors that contribute to these big issues, but just like in real life you dont
need to fix every problem to see improvements in more than one place.
If you address any one cause of issue in drl, you probably end up solving portions of more than one of the
problems that you weren't
trying to fix. For example, if you smell bad during the day you could start
showering every morning. But it doesn't just fix your smell, it clears up your acne too, and your car smells
better,
and then the next thing you know you are the president of the united states.
In deep reinforcement learning it is the same. Solutions to foundational problems usually come in
the form of just
tweaks and additions to the base algorithms as opposed to changing them
in some fundamental way. Then you get magical performance improvements in other areas for free.
In fact, almost all the advancements you will see in reinforcement learning are just additions to the basic
algorithms that you are already familiar with: Actor-Critic and DQN.
There are additions that limit how much the qvalues can change at each update step.
There are additions that vote in the qvalues from multiple networks.
There are even additions that add in artificial curiosity. (we are gonna do curiosity in a later tutorial >:)
But, in this tutorial, we are going to reach for the low hanging fruit.
We are going to address some of the stability issues and forgetting problems our DQN agent currently has.
Instability
By stability issues I am referring to the huge variation in the scores the dqn agent got.
Let's take another look at those total episodic reward's the cartpole Deep Q agent gave us in the last
tutorial.
...
ep 20372: high-score 2762.000, score 240.000, last-episode-time 241 # good
ep 20373: high-score 2762.000, score 48.000, last-episode-time 49 # not good
ep 20374: high-score 2762.000, score 96.000, last-episode-time 97
ep 20375: high-score 2762.000, score 74.000, last-episode-time 75
ep 20376: high-score 2762.000, score 43.000, last-episode-time 44
ep 20377: high-score 2762.000, score 213.000, last-episode-time 214 # great
ep 20378: high-score 2762.000, score 94.000, last-episode-time 95
ep 20379: high-score 2762.000, score 78.000, last-episode-time 79
ep 20380: high-score 2762.000, score 62.000, last-episode-time 63
ep 20381: high-score 2762.000, score 12.000, last-episode-time 13
ep 20382: high-score 2762.000, score 9.000, last-episode-time 10 # terrible
ep 20383: high-score 2762.000, score 12.000, last-episode-time 13
ep 20384: high-score 2762.000, score 53.000, last-episode-time 54
ep 20385: high-score 2762.000, score 60.000, last-episode-time 61
...
In cartpole 200 is actually passable. It is a sign there is a bunch of intentional pole balancing going on.
You can see our agent got scores around 200 a few times.
ep 20372: high-score 2762.000, score 240.000, last-episode-time 241 # good
ep 20377: high-score 2762.000, score 213.000, last-episode-time 214 # great
...and in those 20,000 episodes there were even some fantastic
scores up in the thousands.
high-score 2762.000 # holy shit
But it also got way more totally horrible scores like 12 and 9. Look at that huge streak of scores less than 100
up above.
To give you an idea of how bad a 9 is,
if you take no action the pole falls in 9 steps. It is the minimum possible score. If you make random actions
you are almost guaranteed to get a better score than 9.
Imagine one morning you get into your car to drive to work, but instead of putting the car into reverse to back
out of the driveway, you put it in drive. Then you drive it straight into your living room. But wait you dont
stop there. You hold the steering wheel perfectly straight, foot on the gas, and drive through 8 additional
houses.
The only thing that prevents you
from crashing more is the fact that the 9th house is made of brick. done = True
Would anyone who really knew how to drive do such a thing?
How can the agent be so good sometimes,
and so terrible other times? Is it fair to say the agent knows how to play cartpole at all?
How many retorical questions am i going to ask?
Feature Detectors
This issue where the network is amazing sometimes, but then suddenly terrible, is
often called catastrophic forgetting. To understand the sources of instability that cause
CATASTROPHIC FORGETTING,
it helps to know what is really going on inside the agent's neural network.
"The neural network is making a function that estimates the qvalues." you might say.
Okay, yes, duh, you know that. What does that function look like?
What are the pieces of that function responsible for? Do you know what the network
is actually doing? Can you imagine it's computation in human terms?
Doing so is surprisingly a lot more simple than you might think.
Pattern Finders
If you look at the neurons a bit more thoroughly you can find collections of neurons that function as
detectors of patterns. In image classification these feature detectors trigger on patterns of
pixels.
It starts from simpler patterns like edges and gradients, then the next layer is shapes and corners, and each
successive
layer moves up the ladder of complexity until you are detecting ear shape and position and eventually dog or cat.
If you don't know what im talking about you should go look up feature visualizations in convolutional neural
networks right now.
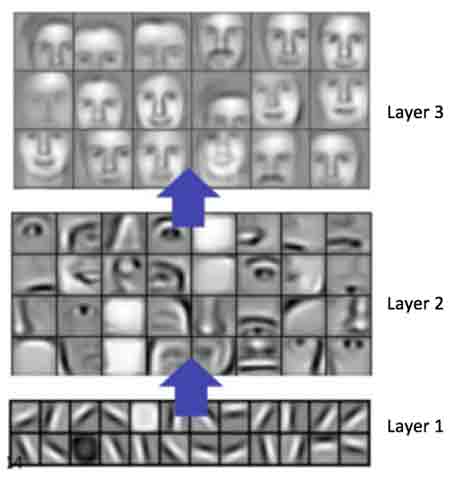
In reinforcement learning it works exactly the same way.
Early layers detect simple patterns. And later layers detect combinations of simpler patterns,
meta patterns.
How does the network pick which pattern to detect? Any pattern in the environment that
influences reward could show up in the network somewhere. In computer vision these patterns are called
features.
If i was an RL (reinforcement learning) agent playing cartpole, I can think of a few feature
detectors
I might want to have:
- "Dangerously-low-pole-angle" is a sign of incoming low reward. So its a good pattern to look for.
I would want a neuron that activates if that happens.
- "Pole-pointing-straight-up" is a good sign of incoming good reward. I better have a neuron that detects
that.
- "Pole-decelerating-while-moving-towards-pointing-up" is a very positive thinking neuron.
- "Pole-rotating-clockwise-while-cart-moving-left" is a sign that if i move the cart to the right, im
gonna get a
low reward, but if i move it left i'll get a high reward. (See how the qvalues work now?)
In the case of cartpole there are no pixels, but the network
detect these patterns by looking at relationships and ranges of the 4 inputs, just the same.
Lets try it ourselves.
Be The Network
The state in cartpole is 4 values. They represent 4 aspects of the cartpole: cart position, cart velocity,
pole angle, and pole angular velocity.
Given a cartpole state, try to describe its behaviour:
state = [0.0, 0.0, 0.0, 0.0] # cart is centered, not moving, pole is centered, not moving
state = [0.0, 5.0, -0.1, -0.1] # cart is centered, cart is moving right, pole is angled to the left, pole is falling left
state = [9.0, 20.0, 0.0, 0.0] # oh shit the cart is going off the right of the screen, qvalues = [1.0, 0.0], GO LEFT
state = [0.0, 0.0, 0.0, 10000.0] # helicopter
You can kind of guess how the network would build these detectors too.
One neuron might compare pole angular velocity to cart velocity, to assert that cart velocity is the greater of
the two.
(It's a good thing, because it means the cart is moving under the pole to catch it from falling)
A couple neurons might be used to detect the cart angle is within a specific range.
You can combine those two features by checking if both those neurons are active at the same time.
In that way you can make a feature detector on the next layer that detects "cart is actively counterbalancing
falling pole".
Weirdly specific specific features, that seem random and useless, can be combined to become more "human" like
patterns down the line.
When you get to the last layers it is slightly different. The final layers might function more like manager
layers.
A neuron in the later layers might take a bunch of different detected features and scale the outputs of them and
send them
to the correct output neuron, the action q value neurons. (I know that's an inverted way of thinking about it, but
metaphorically it is sound.)
Something the last layer might say: "Oh hey the low-pole-angle-neuron and high-tip-velocity-neuron are
active... multiply those outputs by a negative
sign and make them BIG so we output a big low qvalue of -1000 for both the actions, because we are about to lose
the game no matter what!!"
Real Examples
If you think it sounds too human to be true and you are skeptical of my philosophical sounding interpretation of
the behaviours of these neurons, that is okay. It's okay because you don't have to blindly take my word for it.
You can blindly take other people's. There have been a few papers where some people have
investigated specific neurons to try and figure out what makes them activate. The way they do this is they show
the agent a set of states, and then check which neuron activates. Eventually for each neuron you can figure out
what kind of thing that neuron detects.
Here are some examples of individual neurons found in an agent that was tasked with learning pong:
I cant show you the actual neuron obviously because that would just be a huge list of weights, so i'm showing you
pictures of states that make that neuron output a
high number. These states represent the neuron in a way, as they represent the feature that
neuron
detects.
Also each set of states were selected randomly. They arent from the same episode, and didn't necessarily
happen nearby to eachother in time.
Keep in mind smaller features are in neurons in earlier layers, while bigger features are detected by neurons in
later layers. Bigger features are combinations of smaller features.
These concepts are pretty human seeming right?
If you wanted to find out what feature detectors are in your cartpole agent you could go manually position the
cart in various states,
and see which neurons return a high activation. Could be fun.
Valuable Insight
Now you know what's really going on in the agent's neural networks.
But how does it help us solve our stability problem?
Well since learning that the agent is using feature detectors to anticipate low or high rewards for each action,
you might have formed some opinions about the value of some of these features.
Some features are obviously much more useful than others.
Maybe you can see where I'm going with this.
What kind of features are showing up in our cartpole agent?
What kind of features are "best" to solve cartpole?
Why is our agent not making/discovering those features?
Now you are thinking like a researcher.
You've Got Options
When a neural network isn't doing what you want, you have two options:
-
change the neural network
-
change the data
It seems so obvious for other machine learning stuff, but for some reason in reinforcement learning
you just feel like it would be different.
Network
Maybe we need to change the network to get more consistent performance.
Architecture
What influence does the neural network architecture have on the features?
Well, firstly, the same architectural biases apply in reinforcement learning as apply in all the other types
of machine learning. Convolutional networks are biased towards detecting spatial features (or positional
features
if you are including convolving them through time). Recurrent networks are biased towards detecting data
order,
transformations or iterative process features. And fully connected layers aren't biased and so that makes
them good at discovering some types of features but bad at discovering the same feature that just appears
in a different place. You want to design the
architecture to be biased to discovering features you think are useful for the task.
But... a simple fully connected network should be good enough for cartpole.
Loss
You also have the question of the specific loss function. The temporal difference function
biases the agent to assume time functions the way we describe. In our case our agent is designed
to assume that there is always one best action to take, and that we can know it
without knowing anything other than the current environment state. It has no notion of entire "plans" of
actions
or current goal. Maybe it is hard to imagine now, but there
is a lot of black magic that can be done in the loss function that will bias the network to detecting
different features.
I think with some complicated future architectures we could see features that represent exploration strategies
or maybe even predictions of
what happens next in the world. The possibilities are kind of endless.
I know for a fact we don't have to change our architecture to do well consistently in cartpole.
Just from experience.
Network Depth
The more layers the network has, the more complex the features can be. Each layer combines features
from previous layers. So if your network isn't deep enough it might not be able to combine enough simple
features to detect the good meta features.
Again, in the case of cartpole, I don't think this really matters
that much.
Once your network is beyond a few layers the environment just doesnt have any more complicated patterns to
discover.
For a simple environment adding a bunch more layers can have negative effects.
It shrinks the gradient, and most of those layers end up as wasted computation, randomly
splitting features and recombining into feature detectors that were already fully formed and ready to use many
layers before.
Ours is more than deep enough as is.
Layer Width
If the network has more neurons in a layer, then that layer can detect more features.
By more features I mean it has the capacity for detecting more unique patterns in total.
That sounds like bigger would always be a good thing, but how many patterns do you really need to see
to beat cartpole? Is it possible to have the capacity for too many features? The answer is complicated.
There shouldn't really be a limit to the number of possible networks that can beat cartpole, but
I suspect all the good networks have basically the same features within.
Consider a smaller network with a neuron that detects pole angles between 90 degrees, straight up,
and 180 degrees, horizontal pointing right. Compare that to a larger network that is using two neurons for
that same
concept, one neuron detecting 90-135, and another neuron detecting 135-180. Togethor those two neurons in the
larger
network represent an equivalent feature to the one neuron in the smaller network. I would argue that the
single
neuron version is not only more efficient, but more robust. It is unlikely to be repurposed to detect
something else.
Wheras either of those two neurons in the "combo feature" could be easily accidentally repurposed to detect
something else.
That repurposing event is vital to the learning ability of neural networks, but it is
potentially really good
or really bad:
- Bad
because the neurons in the big network are so specific, the new feature will probably be really specific
too, and as such will
be easily grabbed by sudden sharp changes in the environments reward. An overly specific feature is way less
useful than a more
general feature. (I'll get more into that point later.) The fact that big networks have so many available
neurons makes them susceptable to
discovering overly specific features. Guess what overfitting is?
- Bad because when one of the neurons in the combo feature is yanked away to be used in
another feature, the
combo feature breaks. Performance suddenly drops as all the neurons that relied on that feature in
subsequent layers would
become useless, and you would have to wait for that "right side" detector to be remade elsewhere.
- Good because
those two neurons ability to repurpose provides flexibility. Neither neuron is as tied down to that specific
feature,
and so maybe you get lucky and one of them becomes a detector of something much more useful.
The more neurons available, the more chances there are to stumble onto useful features. It's just going to
take more data to find those useful features, and refine the current good ones.
Again, again, again, for cartpole... we shouldn't need that many features. A "Pole-Falling-Left" detector and
a "Pole-Falling-Right" detector should be good enough to balance the pole. It should require very few neurons to
pull that off.
I bet it is so few neurons that you can beat cartpole by manually setting the weights of a tiny network with
less neurons than you have fingers.
(Please, someone out there needs to try this.)
Our network is probably more than big enough to hold every necessary feature to win consistently, and has enough
neurons
available to have a decent change of "getting lucky" and falling into the good features.
Data
So if we don't need to change the network, that just leaves data.
Wait... Data? What am i saying data? We dont get to control our data. The environment provides us
with states and we are just stuck with that.
Behold
The Experience Replay Buffer
To liberate our agent from the shackles of the environment, we can collect a bunch of states and then
treat the big store of states like good old fashioned data. This enables us to do all the tricks you can
do in regular machine learning: batches of data, data shuffling, data augmentation, data analysis, and whatever
else you
can think of.
How does this help our agent discover and develop good general feature detectors?
I will explain in a bit. Now is finally time for some code.
Review
Let's skim back over the code from before to see what our starting point is.
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import gym
import math
import numpy as np
import random
"""Here is our neural network used by the agent:
It takes in a state from the environment
passes it through 3 layers
and then spits out a qvalue for each available action"""
class Network(torch.nn.Module):
def __init__(self, alpha, inputShape, numActions):
super().__init__()
self.inputShape = inputShape
self.numActions = numActions
self.fc1Dims = 1024
self.fc2Dims = 512
"""the feature detectors are all in these"""
self.fc1 = nn.Linear(*self.inputShape, self.fc1Dims)
self.fc2 = nn.Linear(self.fc1Dims, self.fc2Dims)
self.fc3 = nn.Linear(self.fc2Dims, numActions)
self.optimizer = optim.Adam(self.parameters(), lr=alpha)
self.loss = nn.MSELoss()
# self.device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
self.device = torch.device("cpu")
self.to(self.device)
"""this is where the state comes in as x"""
def forward(self, x):
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x """out come the q values ex: [0.4, 0.6]"""
"""Here is our agent:
It holds an instance of a neural network,
and it has some handy functions for choosing an action
and for training its neural network from an input state"""
class Agent():
def __init__(self, lr, inputShape, numActions):
self.network = Network(lr, inputShape, numActions)
"""Observation is an incoming state from the environment.
Asparagus is our exploration strategy.
And the action is just an integer, 1 or 2, the index of the highest q value (the agents choice)"""
def chooseAction(self, observation):
state = torch.tensor(observation).float().detach()
state = state.to(self.network.device)
state = state.unsqueeze(0)
qValues = self.network(state)
action = torch.argmax(qValues).item()
# 10% of the time the agent picks an action at random, and ignores its own q values
chanceOfAsparagus = random.randint(1, 10)
if chanceOfAsparagus == 1: # 10% chance
action = random.randint(0, 1)
# print("qValues: {}, action {}".format(qValues.detach(), action)) # for your convenience, lol
return action
"""The temporal difference function is in here.
This is where the agent predicts qvalues, and then is corrected on what they should have been."""
def learn(self, state, action, reward, state_, done): # input is a SARS "transition"
self.network.optimizer.zero_grad()
state = torch.tensor(state).float().detach().to(self.network.device).unsqueeze(0)
state_ = torch.tensor(state_).float().detach().to(self.network.device).unsqueeze(0)
reward = torch.tensor(reward).float().detach().to(self.network.device)
qValues = self.network(state)
nextQValues = self.network(state_)
predictedValueOfNow = qValues[0][action] # interpret the past
futureActionValue = nextQValues[0].max() # interpret the future
trueValueOfNow = reward + futureActionValue * (1 - done) # td function
loss = self.network.loss(trueValueOfNow, predictedValueOfNow)
loss.backward()
self.network.optimizer.step()
"""This is where we launch our code from.
We make an agent and an environment,
and trap the agent in a loop of 'step'ing the environment.
Training Camp"""
if __name__ == '__main__':
env = gym.make('CartPole-v1').unwrapped
agent = Agent(lr=0.0001, inputShape=(4,), numActions=2)
highScore = -math.inf
episode = 0
while True:
done = False
state = env.reset()
score, frame = 0, 1
while not done:
env.render()
action = agent.chooseAction(state)
state_, reward, done, info = env.step(action)
agent.learn(state, action, reward, state_, done)
state = state_
score += reward
frame += 1
# print("reward {}".format(reward))
highScore = max(highScore, score)
print(( "ep {}: high-score {:12.3f}, "
"score {:12.3f}, last-episode-time {:4d}").format(
episode, highScore, score,frame))
episode += 1
Replay Buffer
Good review. Okay.
See in our main function we are passing the SARS
(state, action, reward, next-state)
transition directly from the environment into the agent.
action = agent.chooseAction(state) # agent picks an action
state_, reward, done, info = env.step(action) # pass action to env, it returns the "RS" of the SARS transition
# (we still have the state from last step) "S"ARS
agent.learn(state, action, reward, state_, done) # and we naively dump it straight into the agent to learn from
Instead of dumping it straight into the agent, lets just collect all the transitions into a list.
state_, reward, done, info = env.step(action)
transition = (state, action, reward, state_) # create the transition
memory.append(transition) # add to a list
You can create the list up at the top of main with the environment and the agent.
Also go ahead and put a batch size constant up there too.
if __name__ == '__main__':
env = gym.make('CartPole-v1').unwrapped
agent = Agent(lr=0.0001, inputShape=(4,), numActions=2)
BATCH_SIZE = 64 # you will see why we need this in a bit
memory = []
All togethor it looks like this.
if __name__ == '__main__':
env = gym.make('CartPole-v1').unwrapped
agent = Agent(lr=0.0001, inputShape=(4,), numActions=2)
BATCH_SIZE = 64 # constant
memory = [] # replay buffer
highScore = -math.inf
episode = 0
while True:
done = False
state = env.reset()
score, frame = 0, 1
while not done:
env.render()
action = agent.chooseAction(state)
state_, reward, done, info = env.step(action)
transition = [state, action, reward, state_, done] # make transition
memory.append(transition) # put it into the memory
agent.learn(memory, BATCH_SIZE) # pass in the memory instead of a single transition
state = state_
score += reward
frame += 1
# print("reward {}".format(reward))
highScore = max(highScore, score)
print(( "ep {}: high-score {:12.3f}, "
"score {:12.3f}, last-episode-time {:4d}").format(
episode, highScore, score,frame))
episode += 1
Rewrite Learn Function Again
Now we are creating a real dataset. That memory will fill up nicely.
But, the agent not receiving single transitions to learn from anymore.
If we want to make it learn from the replay buffer instead, we have to rewrite the agents learn
function
so it can handle batches of transitions instead of just single transitions.
def learn(self, memory, batchSize):
if len(memory) < batchSize: # dont even bother learning if you cant make a decent batch
return
self.network.optimizer.zero_grad()
randomMemories = random.choices(memory, k=batchSize) # randomly choose some memories
# this bullshit just puts all the memories into their own seperate numpy arrays
# # I encourage you to print out each line to see what's going on
memories = np.stack(randomMemories)
states, actions, rewards, states_, dones = memories.T
states, actions, rewards, states_, dones = \
np.stack(states), np.stack(actions), np.stack(rewards), np.stack(states_), np.stack(dones)
# then we have to convert the numpy arrays into tensors for pytorch
# # (also convert the types to floats so pytorch doesn't complain)
# # and also put them on the gpu device
states = torch.tensor( states ).float().to(self.network.device)
actions = torch.tensor( actions ).to(self.network.device)
rewards = torch.tensor( rewards ).float().to(self.network.device)
states_ = torch.tensor( states_ ).float().to(self.network.device)
dones = torch.tensor( dones ).to(self.network.device)
qValues = self.network(states) # compute an entire batch of q values
nextQValues = self.network(states_) # same as above, but for the "next state"
# instead of the current state
batchIndecies = np.arange(batchSize, dtype=np.int64) # an indexing array (will explain later)
nowValues = qValues[batchIndecies, actions] # interpret the past
futureValues = torch.max(nextQValues, dim=1)[0] # interpret the future
futureValues[dones] = 0.0 # ignore future actions if there will
# be no future actions anyways
trueValuesOfNow = rewards + futureValues # same temporal difference but batched
loss = self.network.loss(trueValuesOfNow, nowValues) # same error but along a batch
loss.backward()
self.network.optimizer.step()
Learn Function Inputs
The new learn function takes in the replay buffer and the batch size.
The agent randomly chooses transitions from the replay buffer.
randomMemories = random.choices(memory, k=batchSize)
You don't have to worry about the replay buffer having enough transitions.
Even if k >= len(memory), the random.choices() function still works. You just might
get some repeats.
Minimum Data
If you only have a few transitions stored the batch is not going to be a very good batch.
It's okay to just exit the function until the replay buffer has enough data.
if len(memory) < batchSize:
return
The minimum memory size has important agent performance implications actually. More on that later.
Batched Temporal Difference
The temporal difference section works exactly the same way as before.
It just uses "vectorized" code on arrays of transitions to run a lot faster.
You could have done all this stuff in a for loop, calculating temporal difference
for each transition and then summing/averaging the results togethor before you put
them into the loss function. But python is slow, and so that will be super super slow.
trueValuesOfNow = rewards + futureValues
# that's numpy magic for:
trueValuesOfNow = []
for transition in memoryBatch:
qValues = network(transition.state)
trueValuesOfNow.append(transition.reward + max(qValues))
Notice vectorized code is much shorter. It expresses a lot more in much less code.
Some people find it hard to read at first, and it can be even more fickle to write.
That fickleness usually comes in the form of "pipe-alignment"
work. Thats why theres the whole np.stack()
block np.arange(), and .float() stuff up in the learn function.
Don't feel bad if it often takes you a substantial amount of time to "align your pipes" in numpy.
I'm going to explain each bit of numpy magic used above.
Fickle Nonsense
Numpy and pytorch can be really particular about everything.
They love to complain about array shapes, such as square, triangle, and circle.
And Pytorch especially loves to complain about datatypes.
>>> me = torch.tensor([1,2,3], dtype=torch.Gemini)
>>> her = torch.tensor([4,5,6], dtype=torch.Scorpio)
>>> me + her
Traceback (most recent call last):
File "", line 1, in
TypeError: unsupported operand type(s) for +: 'Gemini' and 'Scorpio'
Pytorch expects your stars to be aligned. Luckily you are god and you have very long arms.
States and rewards should be float type. Thats because your gpu won't like
if they are doubles. I don't know if most gpu's don't have double precision
floating point processing units, or if the torch devs just never implemented
the required infrastructure to use it.
Actions need to be int64 type. That's because you are using them to index tensors.
# batchIndecies is a tensor used to index another tensor
batchIndecies = np.arange(batchSize, dtype=np.int64) # [0, 1, 2, ..., batchSize]
nowValues = qValues[batchIndecies, actions] # actions is a tensor of indecies also
# batchIndecies is indexing the first dimension of qValues
# while the values of actions are being used to index the second dimension of qValues
The first dimension is which transition. The second dimension is selecting either the first or second
qvalue we generated for each transition in the batch.
Indexing tensors with other tensors is something you will have to do all the time.
Anyways, notice how batchIndecies.dtype == np.int64. This kind of stuff is easy to miss.
Pytorch cares.
It works just fine to index numpy arrays with either int32 or int64's. It won't work in pytorch.
# in numpy this shit works fine
>>> a = np.arange(10)
>>> a
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
>>> b = np.arange(5)
>>> b
array([0, 1, 2, 3, 4])
# check the types
>>> a.dtype
dtype('int64')
>>> b.dtype
dtype('int64')
# try indexing as int64
>>> a[b]
array([0, 1, 2, 3, 4])
# try indexing as int32
>>> b = np.arange(5, dtype=np.int32)
>>> b
array([0, 1, 2, 3, 4], dtype=int32)
>>> a[b]
array([0, 1, 2, 3, 4])
# wow it worked
Now try it in pytorch... watch...
>>> a = torch.arange(10)
>>> a
tensor([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
>>> b = torch.arange(5)
>>> b
tensor([0, 1, 2, 3, 4])
>>> a.dtype
torch.int64
>>> b.dtype
torch.int64
>>> a[b] # int64 works just fine
tensor([0, 1, 2, 3, 4])
>>> b = b.int()
>>> b.dtype
torch.int32
>>> a[b]
Traceback (most recent call last):
File "", line 1, in
IndexError: tensors used as indices must be long, byte or bool tensors
# thanks pytorch for the very clear error message
I know you are probably thinking "wow this is crazy specific, why are you telling me this? It's information
overload.
I will never remember this."
I'm telling you this because a lot of the time this is what working with numpy and tensors is actually like.
Behind every happy face in a deep q learning tutorial on youtube that takes 5 minutes to watch is a cold
broken husk of a man that spent 100 hours googling something like this:
RuntimeError: cuda runtime error (59) : device-side assert triggered at ...
Impending Dooooom
From here on out all of the
code is going to be working with vectorized notation. Vectorized states, vectorized state processing,
vectorized experience replay, vectorized loss, vectorized temporal difference functions, vectorized vectorization,
vectorized sleeping, vectorized eating, vectorized pooping, vectorized stack overflowing.
You are definitely going to have to do a bunch of "pipe-aligning" of your own. So I was
worried that if i just show you the code, you
won't realize this type of thinking is going on underneath when writing
this vectorized numpy/tensor stuff. I had to google a whole lot of errors to figure out pipe-alignment at first.
You reading this section may have just saved you 10 hours of time.
Really Good Advice. Seriously, Actually Do This:
So far the best strategy I have for writing vectorized stuff is line by line deliberate programming.
Don't just try random changes to code to fix the numpy/pytorch
pipe-alignment errors. Plan out your data pipeline first. Carefully print each line as your transform the data to
make sure each operation does exactly what you thought it did. If you do it that way you can be sure it will work
on the first try.
And you can avoid days or weeks of the most will-breaking bug searching you can imagine.
After a while you end up seeing way less errors like these anyway.
Probably because you got good at planning your pipes.
But that might never happen if you are just googling random errors. Be deliberate.
Fetching And Formatting Our Memories
Now that you know a little more, check out how it's done in the learn function again.
randomMemories = random.choices(memory, k=batchSize) # randomly choose some memories
memories = np.stack(randomMemories)
states, actions, rewards, states_, dones = memories.T
states, actions, rewards, states_, dones = \
np.stack(states), np.stack(actions), np.stack(rewards), np.stack(states_), np.stack(dones)
states = torch.tensor( states ).float().to(self.network.device) # dtype float32
actions = torch.tensor( actions ).to(self.network.device) # dtype int64
rewards = torch.tensor( rewards ).float().to(self.network.device) # dtype float32
states_ = torch.tensor( states_ ).float().to(self.network.device) # dtype float32
dones = torch.tensor( dones ).to(self.network.device) # dtype bool
I bet you didn't pay much attention to it before, but do you notice the deliberate types now?
See we cast state, reward and states_ to float.
This code is actually getting lucky and the actions end up as dtype=int64 automatically.
The dones array is of type bool. Bool arrays are pretty useful.
You can use them to mask out other arrays for operations.
Check this out:
>>> a = np.ones(4)
>>> a
array([1., 1., 1., 1.])
>>> b = np.array([True, False, True, False], dtype=np.bool)
>>> b
array([ True, False, True, False])
>>> a[b] = 2
>>> a
array([2., 1., 2., 1.])
Look familiar? It should.
nowValues = qValues[batchIndecies, actions] # interpret the past
futureValues = torch.max(nextQValues, dim=1)[0] # interpret the future
'''WE DID IT HERE:
it sets predicted q values to zero if the done is true at that index'''
futureValues[dones] = 0.0 # ignore future actions if there will
# be no future actions anyways
Last Pipe Alignment
If you already know how this part works you can skip this section.
memories = np.stack(randomMemories)
states, actions, rewards, states_, dones = memories.T
states, actions, rewards, states_, dones = \
np.stack(states), np.stack(actions), np.stack(rewards), np.stack(states_), np.stack(dones)
Code does a good job of explaining what this does.
# make fake memories
>>> a = np.arange(25)
>>> a
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16,
17, 18, 19, 20, 21, 22, 23, 24])
>>> a = a.reshape((5,5))
>>> a
array([[ 0, 1, 2, 3, 4],
[ 5, 6, 7, 8, 9],
[10, 11, 12, 13, 14],
[15, 16, 17, 18, 19],
[20, 21, 22, 23, 24]])
# demonstrate stack
>>> pprint(a.tolist())
[[0, 1, 2, 3, 4],
[5, 6, 7, 8, 9],
[10, 11, 12, 13, 14],
[15, 16, 17, 18, 19],
[20, 21, 22, 23, 24]]
>>> a = np.stack(a) # converts a list of lists into a numpy array
>>> a
array([[ 0, 1, 2, 3, 4],
[ 5, 6, 7, 8, 9],
[10, 11, 12, 13, 14],
[15, 16, 17, 18, 19],
[20, 21, 22, 23, 24]])
# demonstrate tuple assignment and Transpose
# # transpose
>>> a
array([[ 0, 1, 2, 3, 4],
[ 5, 6, 7, 8, 9],
[10, 11, 12, 13, 14],
[15, 16, 17, 18, 19],
[20, 21, 22, 23, 24]])
>>> a.T
array([[ 0, 5, 10, 15, 20],
[ 1, 6, 11, 16, 21],
[ 2, 7, 12, 17, 22],
[ 3, 8, 13, 18, 23],
[ 4, 9, 14, 19, 24]])
# # tuple unpacking
>>> sliceOne, sliceTwo = [[1, 2], [3, 4]]
>>> sliceOne
[1, 2]
>>> sliceTwo
[3, 4]
# # all togethor now
>>> states, actions, rewards, states_, dones = a.T
>>> a.T
array([[ 0, 5, 10, 15, 20],
[ 1, 6, 11, 16, 21],
[ 2, 7, 12, 17, 22],
[ 3, 8, 13, 18, 23],
[ 4, 9, 14, 19, 24]])
>>> states
array([ 0, 5, 10, 15, 20])
>>> actions
array([ 1, 6, 11, 16, 21])
>>> rewards
array([ 2, 7, 12, 17, 22])
>>> states_
array([ 3, 8, 13, 18, 23])
>>> dones
array([ 4, 9, 14, 19, 24])
Full Code
Good job if you made it through last section and you understand each line of the learn function.
Here is the full code.
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import gym
import math
import numpy as np
import random
class Network(torch.nn.Module):
def __init__(self, alpha, inputShape, numActions):
super().__init__()
self.inputShape = inputShape
self.numActions = numActions
self.fc1Dims = 1024
self.fc2Dims = 512
self.fc1 = nn.Linear(*self.inputShape, self.fc1Dims)
self.fc2 = nn.Linear(self.fc1Dims, self.fc2Dims)
self.fc3 = nn.Linear(self.fc2Dims, numActions)
self.optimizer = optim.Adam(self.parameters(), lr=alpha)
self.loss = nn.MSELoss()
# self.device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
self.device = torch.device("cpu")
self.to(self.device)
def forward(self, x):
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
class Agent():
def __init__(self, lr, inputShape, numActions):
self.network = Network(lr, inputShape, numActions)
def chooseAction(self, observation):
state = torch.tensor(observation).float().detach()
state = state.to(self.network.device)
state = state.unsqueeze(0)
qValues = self.network(state)
action = torch.argmax(qValues).item()
chanceOfAsparagus = random.randint(1, 10)
if chanceOfAsparagus == 1: # 10% chance
action = random.randint(0, 1)
return action
def learn(self, memory, batchSize):
if len(memory) < batchSize:
return
self.network.optimizer.zero_grad()
randomMemories = random.choices(memory, k=batchSize)
memories = np.stack(randomMemories)
states, actions, rewards, states_, dones = memories.T
states, actions, rewards, states_, dones = \
np.stack(states), np.stack(actions), np.stack(rewards), np.stack(states_), np.stack(dones)
states = torch.tensor( states ).float().to(self.network.device)
actions = torch.tensor( actions ).to(self.network.device)
rewards = torch.tensor( rewards ).float().to(self.network.device)
states_ = torch.tensor( states_ ).float().to(self.network.device)
dones = torch.tensor( dones ).to(self.network.device)
qValues = self.network(states)
nextQValues = self.network(states_)
batchIndecies = np.arange(batchSize, dtype=np.int64)
nowValues = qValues[batchIndecies, actions] # interpret the past
futureValues = torch.max(nextQValues, dim=1)[0] # interpret the future
futureValues[dones] = 0.0
trueValuesOfNow = rewards + futureValues # temporal difference
loss = self.network.loss(trueValuesOfNow, nowValues)
loss.backward()
self.network.optimizer.step()
if __name__ == '__main__':
env = gym.make('CartPole-v1').unwrapped
agent = Agent(lr=0.0001, inputShape=(4,), numActions=2)
BATCH_SIZE = 64
memory = []
highScore = -math.inf
episode = 0
while True:
done = False
state = env.reset()
score, frame = 0, 1
while not done:
# env.render()
action = agent.chooseAction(state)
state_, reward, done, info = env.step(action)
transition = [state, action, reward, state_, done]
memory.append(transition)
agent.learn(memory, BATCH_SIZE)
state = state_
score += reward
frame += 1
highScore = max(highScore, score)
print(( "ep {}: high-score {:12.3f}, "
"score {:12.3f}, last-episode-time {:4d}").format(
episode, highScore, score,frame))
episode += 1
Most of the code in creating the actual experience replay buffer didn't involve the actual
experience replay buffer. The replay buffer was just an array. Almost
everything we coded was just aligning the pipes. FUN.
Did We Really Change Anything?
The neural network gets batches now. Great. Let's see if it had any impact on performance.
...
ep 632: high-score 2275.000, score 1340.000, last-episode-time 1341
ep 633: high-score 2275.000, score 479.000, last-episode-time 480
ep 634: high-score 2275.000, score 389.000, last-episode-time 390
ep 635: high-score 2275.000, score 581.000, last-episode-time 582
ep 636: high-score 2275.000, score 319.000, last-episode-time 320
ep 637: high-score 2275.000, score 256.000, last-episode-time 257
ep 638: high-score 2275.000, score 518.000, last-episode-time 519
ep 639: high-score 2275.000, score 354.000, last-episode-time 355
ep 640: high-score 2275.000, score 423.000, last-episode-time 424
ep 641: high-score 2275.000, score 704.000, last-episode-time 705
ep 642: high-score 2275.000, score 648.000, last-episode-time 649
ep 643: high-score 2275.000, score 612.000, last-episode-time 613
ep 644: high-score 2275.000, score 342.000, last-episode-time 343
ep 645: high-score 2275.000, score 630.000, last-episode-time 631
ep 646: high-score 2275.000, score 730.000, last-episode-time 731
ep 647: high-score 2275.000, score 952.000, last-episode-time 953
ep 648: high-score 2275.000, score 349.000, last-episode-time 350
...
Holy shit look at those scores. Not only are they high, but not a single one is below 200.
We may have addressed the network stability somewhat.
Making Fair Comparisons
Is it really better? We are basically using the same transitions as before.
All we did was just batch the learning. Does this really work or are we being fooled?
Episodic Reward Problems
First we should sanity check ourselves. Is it fair to compare the performance of this agent
at episode 500 to the version with no replay buffer at episode 500? Yes, and no.
In the old version the network only learned from one transition each step.
So on episode 500, if each episode was an average of 80 steps, the agent went through
500 * 80 = 40,000 transitions in total. Compare that to the new agent with memory.
The new version of the agent is calculating error for 64 transitions per step.
So at episode 500, if it had an average of 80 steps per episode, that would be 500 * 80 * 64 = 2,560,000
transitions.
The new agent has done way WAY more processing by episode 500.
In fact, the new agent processes so many transitions per step that it already hits the 40,000 transition mark
by episode 8.
Additionaly, we are assuming that every episode is exactly 80 steps long. That never happens. Every episode
could be drastically
different in duration.
This is a problem. How are we supposed to compare the performance of different agents if
the concept of an episode and the concept of a step is not the same across agents?
To make this even worse, in the agent with no memory, when it has done 40,000 steps it has seen
40,000 unique new transitions. It never reuses even one of them. For an agent with a replay buffer, by the time
it has processed 40,000 steps, the memory
has only collected about 600 transitions. That means some of those transitions could have been reused
over a hundred times.
Sample Efficiency
Instead of using episodes or learn steps, a great way to measure agent performance is with "sample
efficiency".
The sample efficiency of an agent is simple. What performance did that agent achieve by the
time it has seen
x number of unique transitions. The better the performance gained per transition collected, the
better the sample efficiency is.
If you give two different agents 1,000,000 samples, the one that gets better, more reliable performance is the
better agent.
So let's be fair and compare the old agent to the new agent on a per sample basis.
Here I modified the old agent without a replay buffer to print out the number of samples:
"""OLD AGENT CODE"""
if __name__ == '__main__':
env = gym.make('CartPole-v1').unwrapped
agent = Agent(lr=0.0001, inputShape=(4,), numActions=2)
highScore = -math.inf
episode = 0
numSamples = 0 # LOOK HERE
while True:
done = False
state = env.reset()
score, frame = 0, 1
while not done:
env.render()
action = agent.chooseAction(state)
state_, reward, done, info = env.step(action)
agent.learn(state, action, reward, state_, done)
state = state_
numSamples += 1 # increment it every time the agent gets one sample
score += reward
frame += 1
highScore = max(highScore, score)
print(( "total samples: {}, ep {}: high-score {:12.3f}, " # print it out now too
"score {:12.3f}").format(
numSamples, episode, highScore, score,frame))
episode += 1
After running it for a few minutes, here are the results at 50,000 transitions.
...
total samples: 49212, ep 1145: high-score 1094.000, score 198.000
total samples: 49536, ep 1146: high-score 1094.000, score 324.000
total samples: 49828, ep 1147: high-score 1094.000, score 292.000
total samples: 49837, ep 1148: high-score 1094.000, score 9.000
total samples: 49847, ep 1149: high-score 1094.000, score 10.000
total samples: 49856, ep 1150: high-score 1094.000, score 9.000
total samples: 49864, ep 1151: high-score 1094.000, score 8.000
total samples: 49876, ep 1152: high-score 1094.000, score 12.000
total samples: 49885, ep 1153: high-score 1094.000, score 9.000
total samples: 49895, ep 1154: high-score 1094.000, score 10.000
total samples: 49905, ep 1155: high-score 1094.000, score 10.000
total samples: 49915, ep 1156: high-score 1094.000, score 10.000
total samples: 50050, ep 1157: high-score 1094.000, score 135.000
...
That looks like a bad case of CATASTROPHIC FORGETTING.
Now lets modify the new agent code to print out the number of unique samples collected.
"""NEW AGENT CODE"""
if __name__ == '__main__':
env = gym.make('CartPole-v1').unwrapped
agent = Agent(lr=0.0001, inputShape=(4,), numActions=2)
BATCH_SIZE = 64
memory = []
highScore = -math.inf
episode = 0
numSamples = 0 # LOOK HERE AGAIN
while True:
done = False
state = env.reset()
score, frame = 0, 1
while not done:
env.render()
action = agent.chooseAction(state)
state_, reward, done, info = env.step(action)
transition = [state, action, reward, state_, done]
memory.append(transition)
agent.learn(memory, BATCH_SIZE)
state = state_
numSamples += 1 # still only one sample collected per transition
score += reward
frame += 1
highScore = max(highScore, score)
print(( "total samples: {}, ep {}: high-score {:12.3f}, " # and same printing
"score {:12.3f}").format(
numSamples, episode, highScore, score,frame))
episode += 1
And the results at 50,000 samples:
total samples: 45658, ep 227: high-score 1063.000, score 180.000
total samples: 45941, ep 228: high-score 1063.000, score 283.000
total samples: 46332, ep 229: high-score 1063.000, score 391.000
total samples: 46477, ep 230: high-score 1063.000, score 145.000
total samples: 46762, ep 231: high-score 1063.000, score 285.000
total samples: 46955, ep 232: high-score 1063.000, score 193.000
total samples: 47430, ep 233: high-score 1063.000, score 475.000
total samples: 47929, ep 234: high-score 1063.000, score 499.000
total samples: 48512, ep 235: high-score 1063.000, score 583.000
total samples: 48835, ep 236: high-score 1063.000, score 323.000
total samples: 49019, ep 237: high-score 1063.000, score 184.000
total samples: 49897, ep 238: high-score 1063.000, score 878.000
total samples: 50092, ep 239: high-score 1063.000, score 195.000
Look at that stability.
Notice, it has only played 239 episodes whereas the other one was on episode 1157.
And even though the stability has changed, the high score is similar. Perhaps that has to do with us having a
very similar distribution of transitions collected.
After all, what is in the data matters a lot, not just how much of it there is. The cartpole environment should
be providing
very similar transitions to both agents.
Now, if we were really good scientists we would use the same set of transitions on both agents, and identical
starting weights
and frozen random seeds for the environment. I think that is overkill and if you run these 2 agents 100 times
each
you won't become any less confident about the following conclusion:
An Experience Replay Buffer can increase the sample efficiency of a deep q agent.
Wall Clock Time
Something else to consider is runtime.
Both agents can be considered on a per sample basis, however, the version with the replay buffer takes
substantially longer
to run each update step. Running on cpu it should take somewhere between 1 and 80ish times as long to process
one step of a network update. I had to wait quite a bit longer for the memory agent to hit the 50,000 samples
mark.
Whereas the agent without a replay buffer hit 50,000 samples in less than a minute. I didn't even have enough
time to make a
sandwhich.
Part of this slowness has to do with our naive implementation of the replay buffer, which we will fix another
time.
But, we did legitimately increase the amount of computation necessary to train the agent on an equivalent amount
of experience.
This difference in training clock time doesn't matter once you deploy the agent. Once the
agents are trained up to your satisfaction you can disable the learn function and just let the agents play
"offline".
Both agents take equally long to pick actions if they arent learning. (But the agent trained with the memory
will get much better scores. :^)
Do All Three
For these reasons, when you see RL papers comparing agents, often times they will contain graphs of "reward per
episode",
"reward per sample", and "reward per time". Having all three methods of comparison ensures you are getting a
more fair assessment of performance between agents.
It Is Also Just Plain Better Though
The new agent is way better in general. The features in the old agent would decay so fast from the poor dataset
that
they never got a chance to get refined. You can think of it like a persistant force of chaos always pressing down
on the
weights of the neural network at each step. The old agent's feature detectors were always taking one step forward,
two steps back.
It's highly likely you could train the old agent for days and it would never get as good as the new one with the
replay buffer.
What's Next
Before you go off looking for the next upgrade to your agent, you should
assure that you really understand why adding the replay buffer improves performance so drastically.
I know you are probably wondering why it works at all given that we didn't really change much.
It is the same amount of transitions as before, after all... just in a different order...
I want you to think about it for yourself first as I will go deeply into this in the next tutorial.
For now I will leave you with some questions...
- How come in classification tasks in typical machine learning you should always shuffle your data?
- Why in both computer vision and NLP is data usually batched or minibatched? Does it improve performance?
Or is it only done for compute speed?
- Why in typical machine learning is it important to have balanced data? Ex:
If it is a classification task, why do you want equally as many images of cats as of dogs?
Is it okay to have 10,000 pictures of dogs, but only 100 pictures of cats?
-
What does it mean for an agent to generalize instead of memorize?
-
Why is my wife spending the weekend at her mothers house?
If you can answer these questions, there's a good chance that you just might know how to read english.
Tutorial Hub








